
© 2024 Petroportal.ru
Классификация по сейсмическим атрибутам
Атрибуты, извлечённые из сейсмических данных, помогают выделить зоны с изменяющимися характеристиками волнового поля, идентифицировать геологические объекты, оконтурить аномальные зоны и т.д. На сегодняшний день разработан солидный математический аппарат, предназначенный для получения дополнительной информации из сейсмических данных.
На практике часто бывает, что определённый сейсмический атрибут может дать блестящие результаты для одного месторождения и не дать положительного результата на соседнем месторождении. Поэтому перед интерпретатором встаёт довольно субъективная задача выбора информативных для конкретного месторождения сейсмических атрибутов. Здесь может быть полезным инструмент нейронных сетей, который позволяет проанализировать данные, восполнить недостающие данные, найти неявные связи между различными типами данных и расклассифицировать территорию на однородные области.
Познакомимся с этим инструментом.
Часто считается, что если упругие свойства выдержаны по латерали, то волновое поле, а следовательно, и сейсмические атрибуты не должны претерпевать сильных изменений. Поэтому, если мы видим значительное изменение сейсмического атрибута, мы можем предположить, изменение упругих свойств в этой области. На этом принципе основано районирование территории на области, которые различаются друг от друга упругими свойствами и, соответственно, фациальным составом.
На практике эта задача реализуется следующим образом: интерпретатор рассчитывает множество сейсмических атрибутов, анализируется корреляционная матрица между всеми атрибутами, отбраковываются атрибуты, между которыми очень низкий коэффициент корреляции, так как между ними нет связи, а также отбрасываются атрибуты с очень высоким коэффициентом корреляции, так как они явно дублируют друг друга и не несут новую информацию. Далее, интересующая территория разделяется на однородные области по группе атрибутов (коэффициент корреляции +/- 0.5-0.8).
Методика классификации по сейсмическим атрибутам
*все данные взяты из книги "Практикум по сейсмической интерпретации в Petrel"
В закладке Processes, в разделе Utilities запустите процесс Train estimation model.
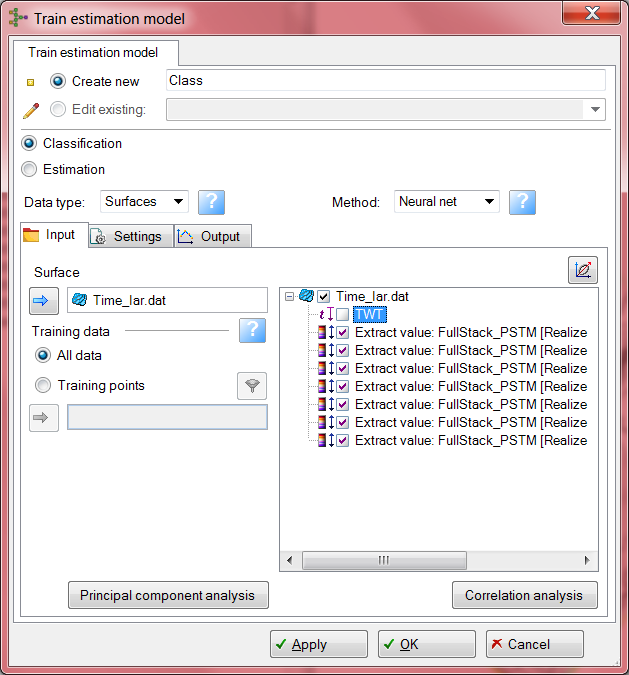
3. Чтобы проанализировать коэффициенты корреляции между атрибутами нажмите кнопку Correlation analysis. Появится корреляционная матрица, в зависимости от величины коэффициенты корреляции окрашены в разные цвета. Проанализируйте таблицу, атрибуты с очень низким или очень высоким коэффициентом корреляции могут быть исключены из процесса классификации.
4. 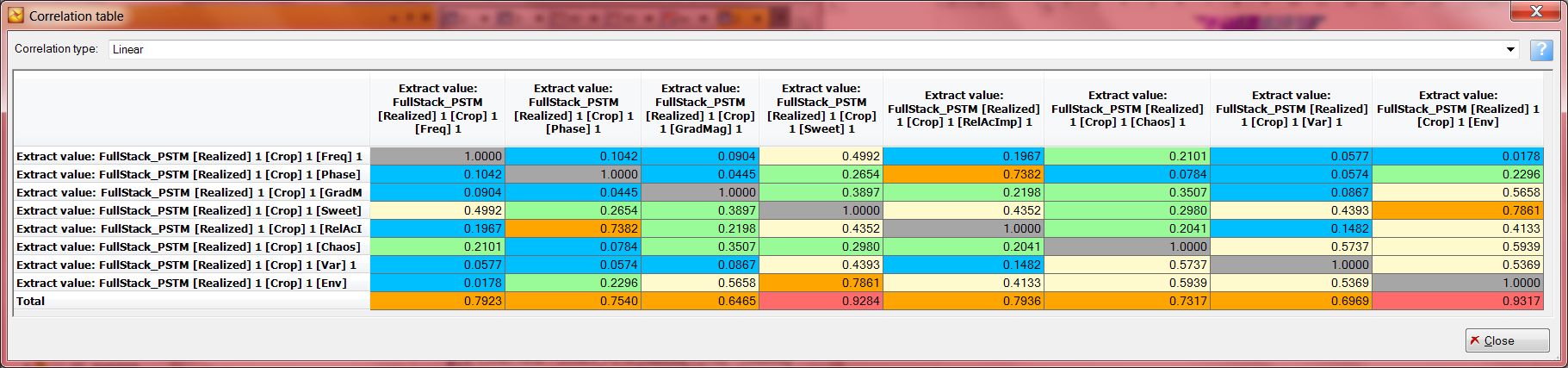
5. Следуя рекомендации по отбраковке сейсмических атрибутов следует отключить Sweetness и Envelope, т.к. у этих атрибутов слишком высокая сходимость.
6. Далее перейдите в закладку Settings, укажите количество классов Unsupervised 5, а количество итераций Max number of iteration 100, остальные параметры оставьте по умолчанию. Нажмите Ok.
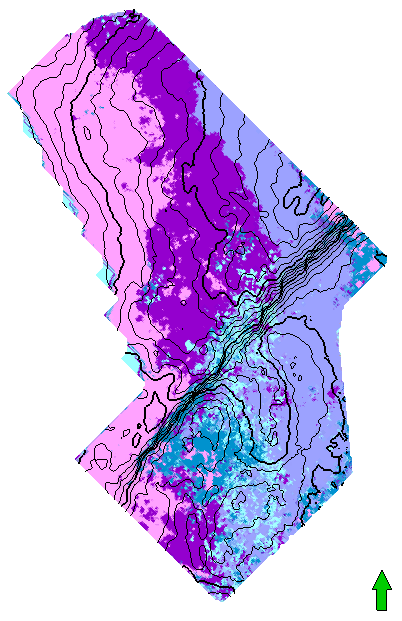
7. Отобразите классификацию, которая появилась в виде нового атрибута поверхности "Time_Iar.dat" -> General discrete [Class].
Существует ещё один способ уменьшить влияние похожих атрибутов на результат классификации – метод главных компонент (все используемые атрибуты формируют многопризнаковое пространство, которое делится на компоненты; каждая компонента имеет разную информативность):
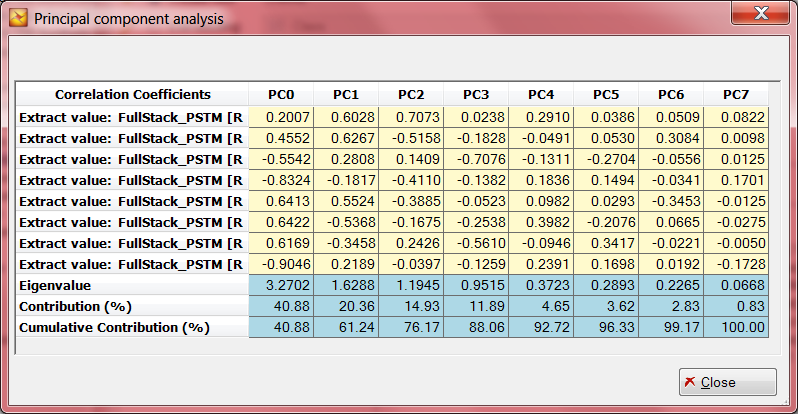
3. Оцените вклад каждой компоненты Contribution и определитесь, сколькими компонентами можно пренебречь. В нашем случае, пятая и шестая компонента не несут никакой смысловой нагрузки (Cumulative Contribution=100%) и их можно отбросить.
4. Нажмите кнопку Use PC  и уберите галочки с 6 и 7 компоненты, которые мы не хотим использовать.
и уберите галочки с 6 и 7 компоненты, которые мы не хотим использовать.
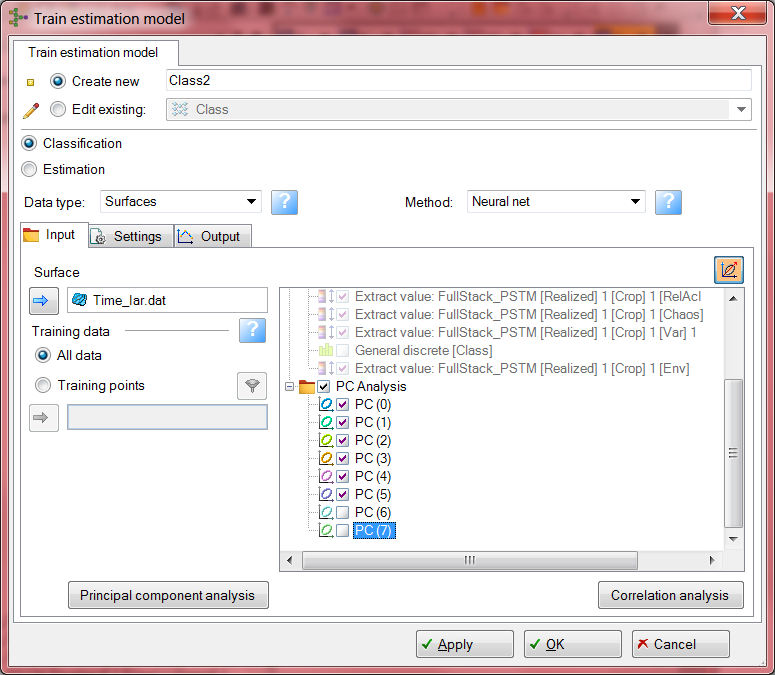
6. Отобразите классификацию, которая появилась в виде нового атрибута внутри рассчитываемого горизонта "Time_Iar.dat".
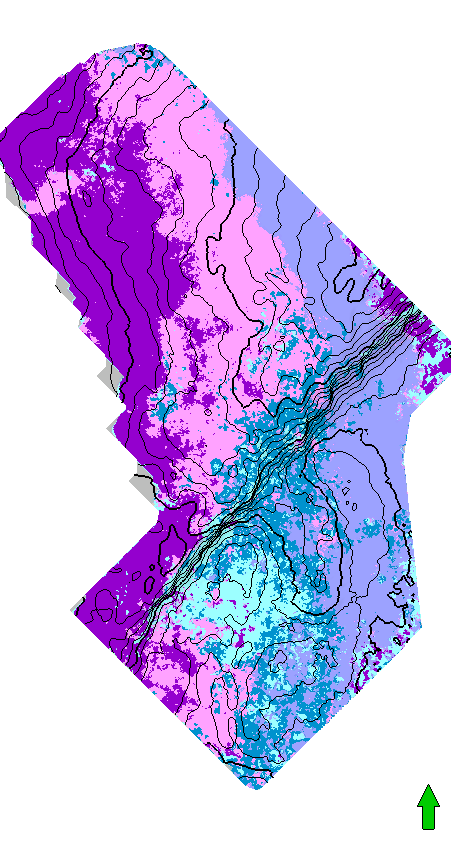
Полученные карты классификации можно использовать для геологического районирования и изучения изменения фаций на исследуемой площади.
Станьте первым!